
Claris FileMaker Pro 19 から Apple の Core ML による機械学習が利用できるようになりました。本ブログ・シリーズでは、FileMaker ビギナーズ & ジュニアズのみなさんに、FileMaker での機械学習がどういうものか、何ができるのか、どうやって使うのかなどについてざっくりご紹介します。
シリーズ 1 回目のブログでは、機械学習とは何か、FileMaker で機械学習を利用するということはどういうことかなどについて、これまでに公開されているセミナー動画とともにご紹介しました。シリーズ 2 回目の前回は、学習済みの Core ML モデルを使ってFileMaker に機械学習機能を取り込む基本的な方法についてご説明しました。
今回はいよいよ、自分用の機械学習モデルを作って、カスタム App に組み込みます。
…といっても、難しいことは一切なし! Apple から提供されている Core ML モデル開発ツール Create ML を使うことで、ノーコードで機械学習モデルを作ることができます。
今回の旅路:
- Create ML とは
- Tabular Regression テンプレートを使う
- Create ML で解約可能性予測モデルを作る
- 機械学習結果を確認する
- 顧客情報管理 App に Core ML モデルを組み込む
- 解約可能性を取得するスクリプトを作る
- 動作を確認する
- できました
なお、このブログ・シリーズでご紹介する機械学習機能は、FileMaker Pro 19 以降の macOS 版でご利用いただけます。19 よりも前のバージョンをお使いの方は、最新の無料評価版をダウンロードしてご利用ください。
Create ML とは
Create ML は Core ML モデルの開発ツールで、mac OS 上で利用可能な Apple の開発ツール Xcode 11 以降に同梱されている Core ML モデル開発ツールです(Xcode は App Store から無料でダウンロードできます)。
「開発ツール」というと、なんだか難しそうな、めんどくさそうなイメージが湧きがちですが、Create ML の場合は、学習データを用意し、テンプレートに入力して学習させるだけで、簡単に、なんとノーコードで Core ML モデルを作成することができます。
Create ML の起動
Create ML のテンプレートは、Image や Video など 6 つのグループに分類されており、全部で 11 個あります(2021 年 3 月現在)。Create ML を起動後、最初に現れるファイル選択ダイアログで [New Document] を選択するか、[File] メニューから [New Project] を選択するかすると、作成するモデルのタイプごとのテンプレートの一覧が表示されます。
Create ML のテンプレート (All)
前回、前々回のブログでもご説明したとおり、残念ながら FileMaker ではこれら 11 個のテンプレートで作成したすべての Core ML モデルを利用できるわけではありませんが、Image Classification(画像分類)テンプレートについては、モデルの作成方法と FileMaker での利用方法について動画で紹介されていますので、ぜひ視聴してみてください。
参考動画:
- Core ML で画像を自動判別する(株式会社寿商会)
- FileMaker で機械学習モデルを使う(株式会社未来Switch)
また、Create ML の使い方については、次のドキュメントや動画も参考にしてください。
- 画像分類モデルの作成(Apple Developer ドキュメント)
- Create ML App の紹介(日本語字幕付き)
FileMaker に予測機能を組み込む
Create ML には「Table」(表)というグループに 3 つのテンプレートが提供されています。今回はその中の Tabular Regression テンプレートを使って、顧客情報を管理するカスタム App に顧客の解約可能性を予測する機能を組み込んでみましょう。
Tabular Regression テンプレート
Tabular Regression テンプレートは、表形式のデータを学習して数値予測をするモデルを作成することができます。FileMaker のベースはリレーショナルデータベースなので、テーブル(表)データをそのまま機械学習の入力に使うことができ、Tabular Regresion の使い道もいろいろありそうですね。
今回使用する顧客情報管理 App は、ある会社の顧客情報を、顧客情報テーブル、契約情報テーブル、支払いテーブルなどを使って管理する、ごくごく普通のカスタム App です。このカスタム App に、解約に関係しそうな数値フィールド、集計フィールドなどを集めたダッシュボードのレイアウトを作り、その中に機械学習を使って予測した解約可能性を「現在の解約可能性」として表示できるようにします。
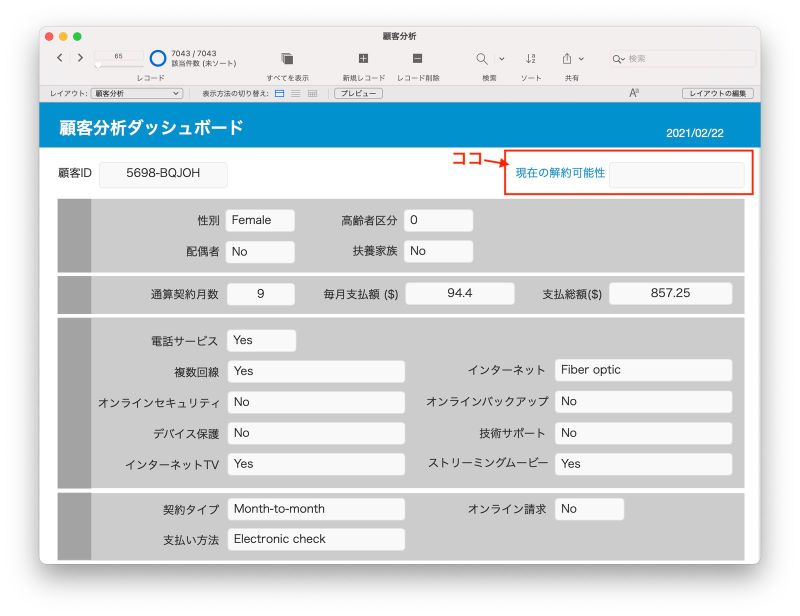
カスタム App で解約可能性を予測する
なお、この顧客情報管理 App 用のサンプルデータとして、Telco Customer Churn (Kaggle) というデータセットを使いました。このデータセットには、7,043 人の顧客について、性別、高齢者かどうか、配偶者の有無などの個人情報の他、通算契約月数、毎月支払額、サービス内容、契約タイプ、支払い方法などの契約情報、そして、実際に解約したかどうかの情報など 21 個の属性が入っています。
Create ML で解約可能性予測モデルを作る
では、いよいよ Create ML で解約可能性を予測する Core ML モデルを作りましょう。
最初に、Create ML で Tabular Regression テンプレートを選択して新しいプロジェクトを作ります(上の「Create ML とは」の画面イメージを参照してください)。
プロジェクトが作成されると、以下のようなテンプレート画面が表示されます。上部に表示されている「Settings」「Training」「Evaluation」「Preview」「Output」の各画面上でモデルを作成していきます。
Tabular Regression テンプレート
まず、このテンプレートの「Settings」上で、モデル作成に使用する学習データ(Training Data)とテスト用データ(Testing Data)を設定します。これらは CSV 形式のファイルで、先頭行に、モデルを作成する際に使用する属性名が必要です。なお、FileMaker のレコードをエクスポートしてデータファイルを作成する際は、FileMaker Pro の [ファイル] メニューの [レコードのエクスポート…] で「Merge ファイル」としてエクスポートし、エクスポートしたファイルの拡張子(.mer)を「.csv」に変更すると簡単です。
データの設定は、画面上の「+」をクリックしてもいいし、「Choose」と表示されているドロップダウンリスト中の「Select Files…」を選択してもいいし、データファイル(csv)をそのままドラッグ&ドロップしても構いません。この辺りは他のテンプレートを使った場合と同じなので、先にご紹介した参考動画等も参照してください。
今回は、カスタム App(顧客情報管理 App)に保存している元のデータのうち、学習データに 4,992 件、テスト用データに 1,997 件をそれぞれ割り振ることにしました(欠損値があったデータを除外したり、後述の Preview 用のデータを別に取り置いたりしたので、半端な数になっています)。
なお、学習(Training)の過程で検証用データ(Validation Data)が必要になりますが、画面中央の「Validation Data」を「Automatic」のままにしておくと、Create ML の方で自動的に学習データから適切な数のデータを検証用に回してくれるようです。
データファイルを設定すると Create ML が即座にファイルを読み込み、「Target」(予測する値)と「Features」(機械学習に使う属性)に対して、ファイルの先頭行に記載された属性名がドロップダウンリストで選択できるようになります。
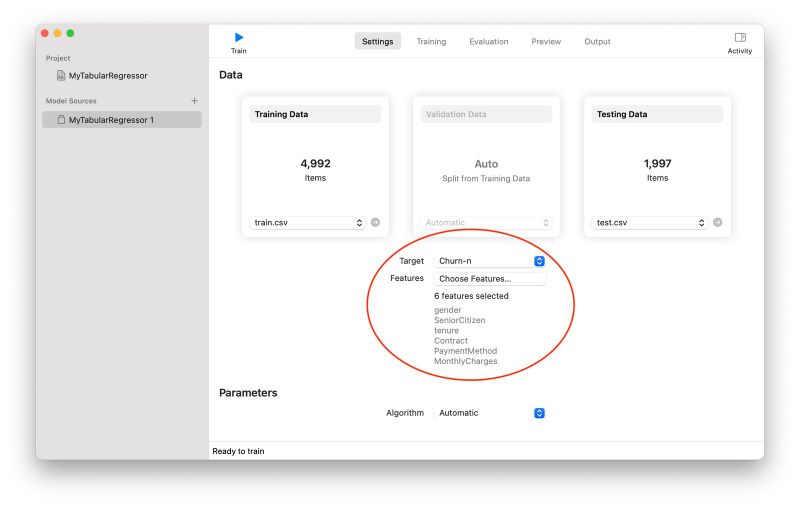
モデル作成(学習)のための設定
ここでは、上の画面イメージのとおり、「Target」として、解約したかどうかの属性(Churn-n)を、「Features」として、顧客の性別(gender)、高齢者かどうか(SeniorCitizen)、通算契約月数(tenure)など 6 つの属性を選択しました。
なお、元々のデータ(FileMaker のテーブル)では、解約したかどうかの属性(Churn)はテキストタイプ(”Yes”/”No”)なのですが、この Tabular Regression テンプレートでは「Target」として数値タイプの属性しか選択できないので、解約した場合としていない場合をそれぞれ「1」、「0」とする属性(Churn-n)を追加して使用しました。
テンプレート画面下「Parameters」の「Algorithm」は、「Automatic」の他、ドロップダウンリストから「Random Forest」、「Boosted Tree」、「Decision Tree」、「Linear Regression」の 4 つの回帰分析手法が選択できるようになっています。今回は「Automatic」のままにしておきます。
機械学習結果を確認する
データファイルや属性などの設定が終わったら、画面左上の青い矢印「Train」ボタンをクリックします。
今回は、「Train」ボタンをクリックした瞬間、自動的に「Training」画面に移動したかと思ったら、すぐに下の画面のような表示になりました。もう学習が終わってしまったようです。
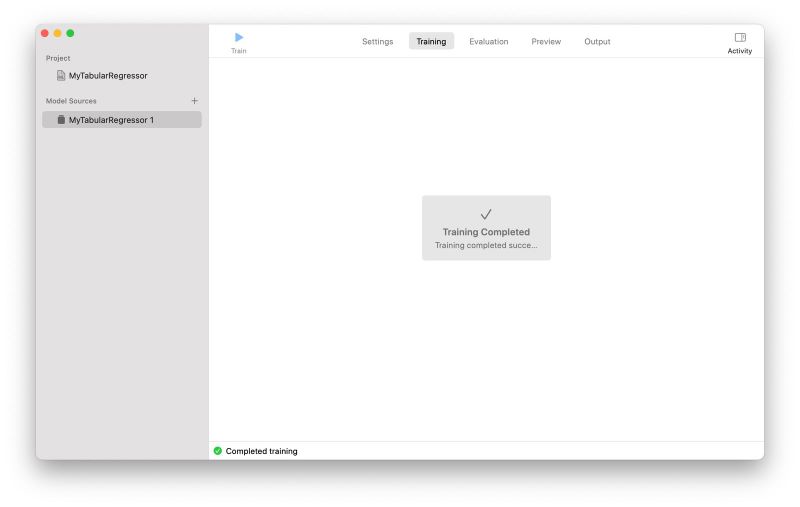
学習終了
おおお、と眺めていたら、その後またすぐに自動で「Evaluation」画面に移動し、テスト用データを使ったテストが始まりました。そして、これもすぐ終わって、作成したモデルの評価結果(精度指標)として最大誤差(Maximun Error)と RMSE (Root Mean Square Error; 二乗平均平方根誤差)が画面に表示されました(これらの評価値を使って複数のモデルの良し悪しを比較することができます)。
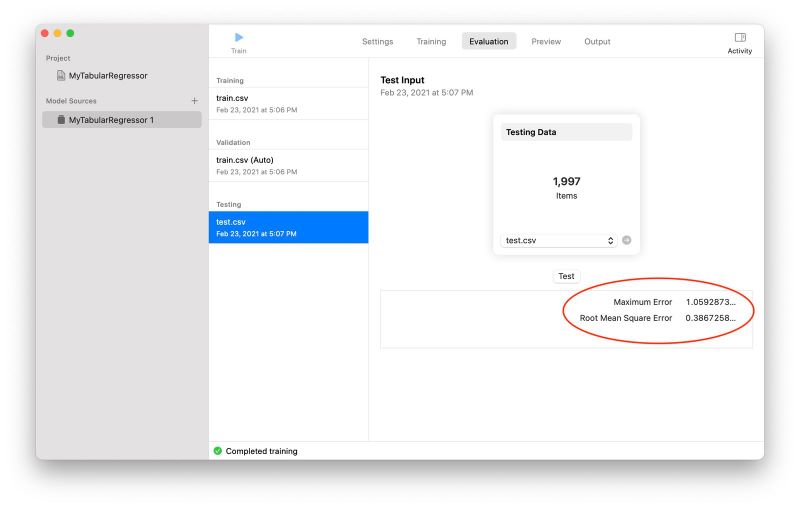
モデルの評価結果
これで Create ML によるモデル生成処理は終わりです。
この段階で「Output」画面に(今度は手動で)移動して、生成された Core ML モデルを取り出すことができます。今回生成されたモデルのサイズは、画面上に「1 KB」と表示されているように、とても小さいです。モデルのメタデータ(Metadata)には、最初に Create ML のプロジェクトを作成したときに入力した Description と Author が登録されていることがわかります。
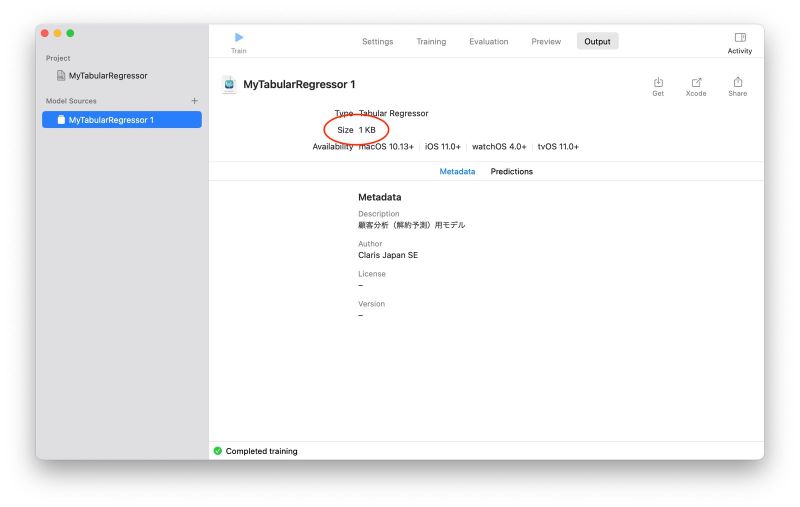
作成された Core ML モデルの概要
生成されたモデルは、「Output」画面の左上のモデル名(上の画面では「MyTabularRegressor 1」)の左横のアイコンをドラッグ&ドロップすることでも取り出せますし、画面右上の「Get」をクリックしてフォルダに書き出すことでもできます。
ここで、「Output」画面右上の「Xcode」をクリックすると、Xcode が起動して、作成された Core ML モデルを Xcode 上で扱えるようになります。下の画面イメージのように、Xcode ではモデルについての詳細情報や入出力も確認することができます。「Predictions」タブを開くと、このモデルは作成したモデルは 6 つの特徴量を入力とし、「Churn-n」名前で数値(Double)を 1 つ出力するものであることがわかります。
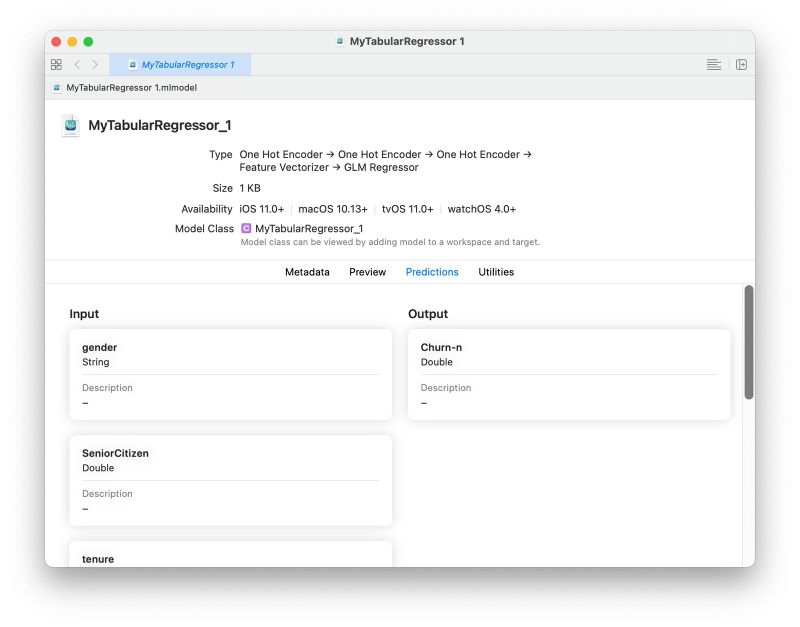
Xcode でモデルを概観する
また、Netron という機械学習モデルの可視化ツールを使うと、作成された Core ML モデルの入出力仕様とモデルの構造を概観することができます。Netron の画面の右側のパネルからも、このモデルの入力は 6 つの特徴量で、出力は「Churn-n」という名前の 1 個の数値(float64)であることがわかります。
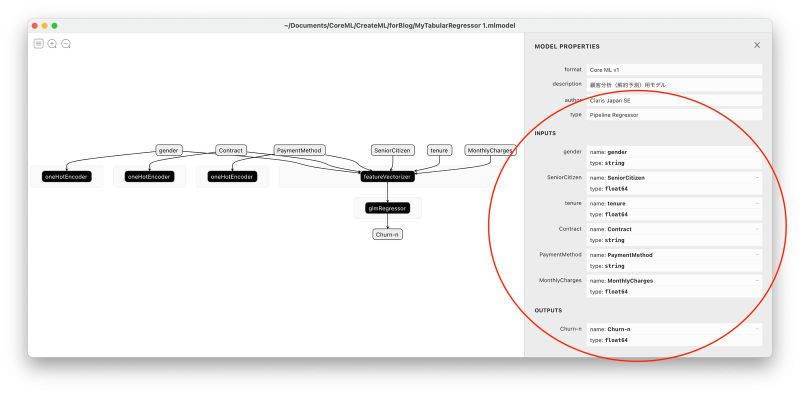
Netron でモデルを可視化する
この辺で Create ML に戻って、作成したモデルがどんな推論をするのか試してみましょう。
Create ML の「Preview」画面では、出来上がったモデルの予測結果をその場で確認することができます。以下の画面は、学習データにもテスト用データにも使っていない 16 個のデータ(csv)を入力してみたものです。それぞれのデータについて予測した値(Prediction)を順にプレビューできるようになっています。
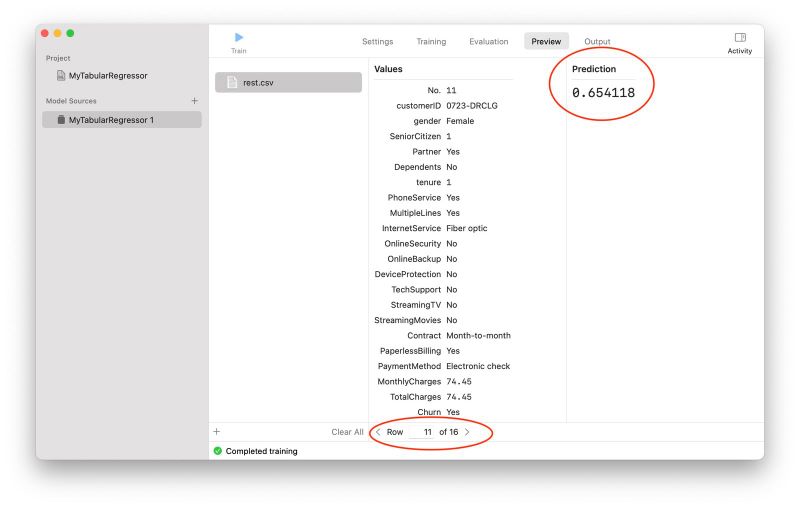
モデルのプレビュー
もし、プレビューした結果が気に入らなかったら、同じプロジェクトの中で、学習データ(Training Data)、特徴量(Features)、あるいはアルゴリズム(Algorithm)を変えた別のモデルを作成することもできます(下の画面では「MyTabularRegressor 2」という新しいモデルができています)。複数のモデルができたら、「Evaluation」画面での評価結果を比較したり、「Preview」画面で実際のデータで確かめたりすることができるので、試行錯誤で最適なモデルを作成するのに CreateML はとても便利ですね。
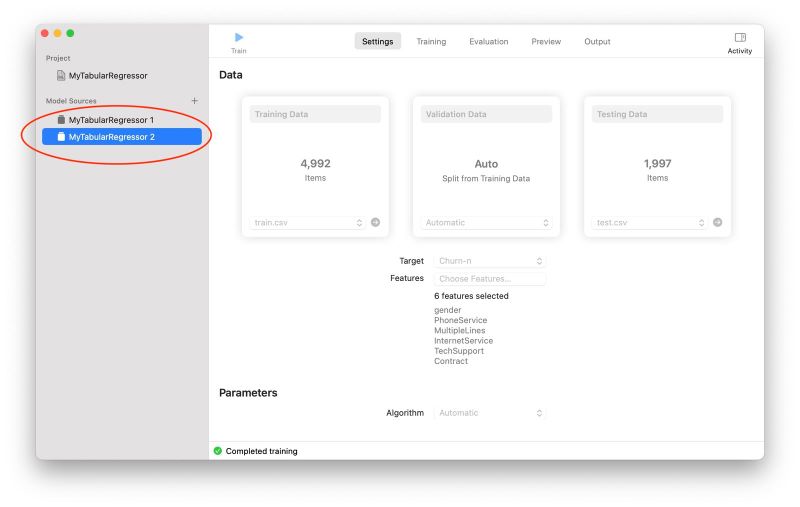
別のモデルも試す
顧客情報管理 App に Core ML モデルを組み込む
顧客の解約可能性を推論する Core ML モデルが出来上がったので、これを顧客情報管理 App に組み込みます。
顧客情報管理 App で解約可能性を表示する「顧客分析ダッシュボード」レイアウトには、モデルが計算した解約可能性を保存するフィールドの他、少なくとも以下の 6 つのフィールドが配置されているものとします。これら 6 つのフィールドの値はモデルへの入力となり、計算に使用されます。
- モデルでの計算に使用するフィールド
- CustomerSummary::gender (性別)
- CustomerSummary::SeniorCitizen(高齢者区分)
- CustomerSummary::tenure(通算契約月数)
- CustomerSummary::Contract(契約タイプ)
- CustomerSummary::PaymentMethod(支払い方法)
- CustomerSummary::MonthlyCharge(毎月支払額)
- モデルでの計算結果を保存するフィールド
- CustomerSummary::MLResult(現在の解約可能性)
Core ML モデルは、グローバル格納フィールド「CustomerSummary::model」に保存しておきます。
解約可能性を取得するスクリプトを作る
次に、「CustomerSummary::MLResult」フィールドに Core ML モデルを使って計算した解約可能性を設定するスクリプトを作成します。
今回は利用する Core ML モデルのサイズが小さいので、1 つのスクリプトで、モデルをロードして計算し、アンロードする一連の流れを実行することにします。モデルのサイズが比較的大きく、ロードに時間がかかるようであれば、モデルをロードするだけのスクリプトを最初に実行して、以降、モデルで計算する別のスクリプトを何度も使うようにしても良いかもしれません。その場合は、適切なタイミングでアンロードしてリソースを解放するのをお忘れなく。詳しくは、前回のブログの説明を参照してください。
今回作成したスクリプトは、次のものです。

今回作成したスクリプト
上記スクリプトを順に見ていきましょう。
まず最初に、[機械学習モデルを構成] スクリプトステップを使って Core ML モデルをロードします。このとき、[処理] オプションには、前回のブログで使ったビジョンモデルの場合([視覚]を指定)とは異なり、 [一般] を指定します。[名前] は何でも良いので、ここでは「TabularRegressionModel」としました。
#1. 機械学習モデルをロードする
機械学習モデルを構成 [ 処理: 一般 ; 名前: “TabularRegressionModel” ; 次から: CustomerSummary::model ]
次に、ComputeModel 関数を使って、ロードしたモデルにより解約可能性を計算します。今回のモデルはビジョンモデルではなく一般モデルなので、次の構文になります。第一引数の [モデル名] の後が、前回のブログで使ったビジョンモデルのと違いますね。
第二引数以降は名前と値のペアを 1 個以上記述する仕様で、どのような名前と値を記述するかは、利用するモデルによって異なります。今回使用する Core ML モデルは、”gender”, “SeniorCitizen” などの 6 つの特徴量を使うので、次のように、6 つの属性名(フィールド名)とその値(フィールド値)のペアを引数として与えます。

計算結果をいったん変数に設定
上のステップでは ComputeModel 関数の計算結果をいったん変数「$result」に設定しているので、続いて、この計算結果から目的の解約可能性の値を取り出します。
今回のモデルは解約可能性の値が属性「Churn-n」の値として出力されるので、ComputeModel 関数の出力は、「Churn-n」をキー、解約可能性を値とする JSON 形式となります。この JSON テキストの中から目的の値を JSONGetElement 関数で取り出し、「CustomerSummary::MLResult」フィールドに設定します。
フィールド設定 [ CustomerSummary::MLResult ; JSONGetElement ( $result ; “Churn-n” ) ]
最後に、使用した Core ML モデルをアンロードします。
機械学習モデルを構成 [ 処理: アンロード ; 名前: “TabularRegressionModel” ]
できあがったスクリプトは、「顧客分析ダッシュボード」レイアウト上でフィールド値が更新されたら実行されるよう、同レイアウトに [OnRecordLoad] と [OnRecordCommit] スクリプトトリガを使って設定しておきます。
動作を確認する
ではいよいよ、作成したスクリプトを動作させてみましょう。
ある顧客のデータを表示すると、レイアウトの右上に「現在の解約可能性」として値が表示されます。
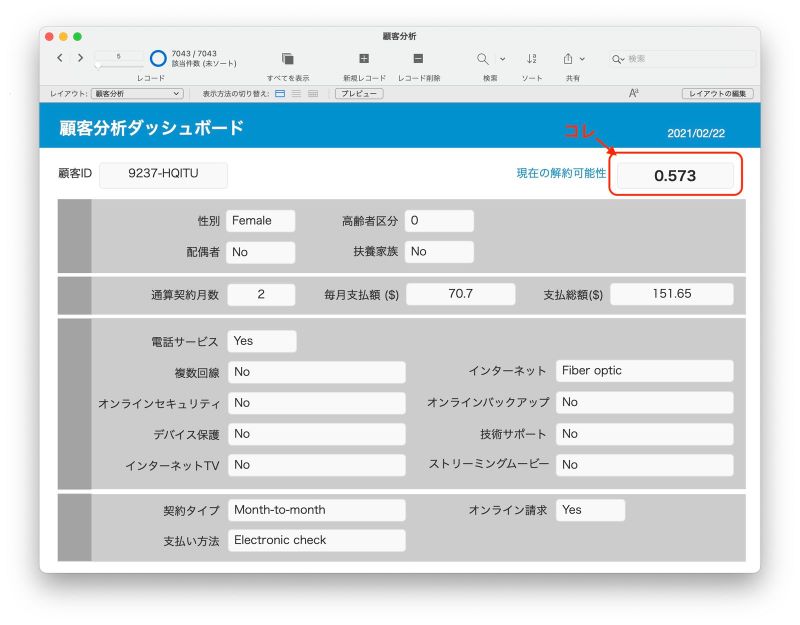
元の解約可能性の値
スクリプトは無事、動いているようです。めでたし!
この顧客の現在の解約可能性は「0.573」とありますが、どうでしょう、数値としては若干高いでしょうか。
ここで、「契約タイプ」の値を「Month-to-month」(月払)から「Two year」(2 年契約)に変更してみます。そうすると、解約可能性は「0.441」と少し小さくなりました。つまり、この顧客に対しては契約タイプの変更を提案して 2 年契約にしてもらうと、解約可能性が小さくなる可能性があると予想されます。
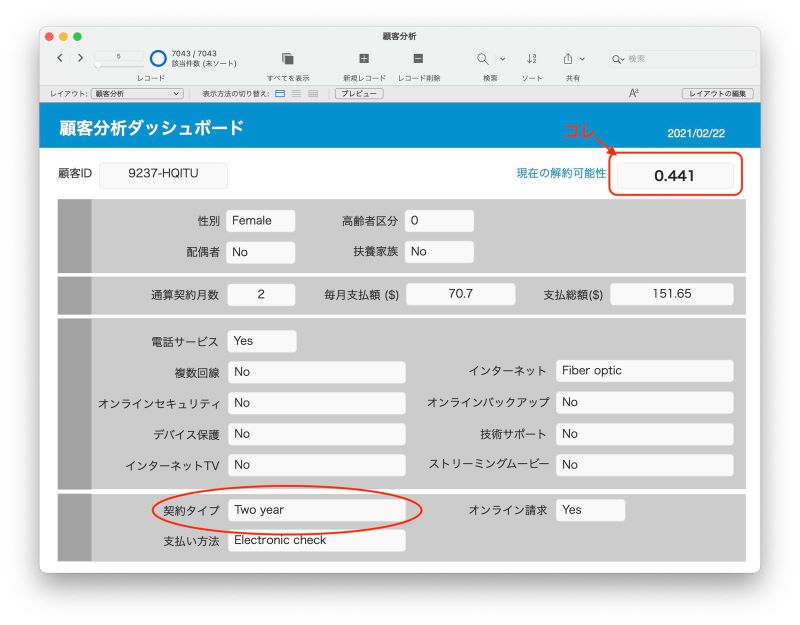
「契約タイプ」を変更した場合の解約可能性
さらに、「通算契約月数」の値を「12」に変更してみると、解約可能性はさらに小さく「0.391」になりました。この顧客はまだ契約して 2 か月しか経ってませんが、12 か月間どうにか契約を継続してもらえたら、さらに解約可能性が小さくなると予想される、ということですね。キャンペーンやイベント案内を積極的に送ることにしましょう。
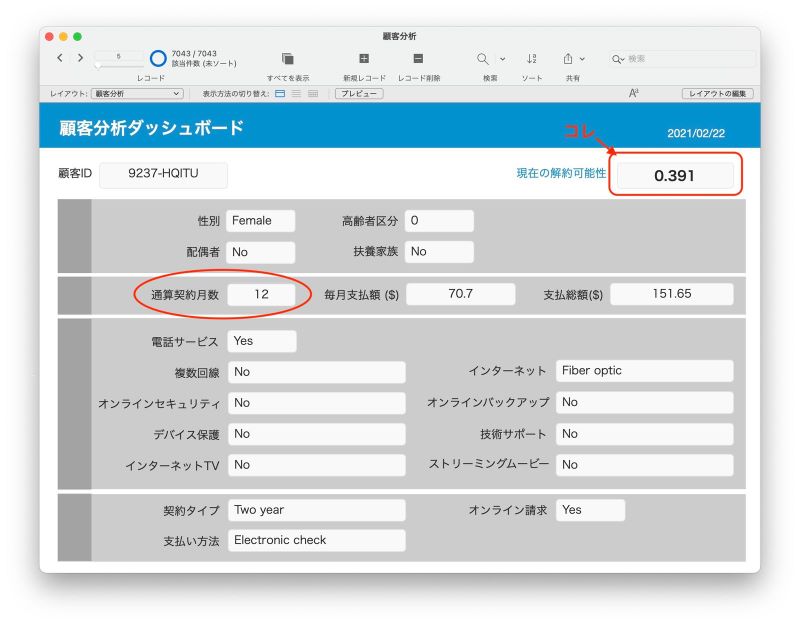
解約可能性がさらに小さく
このように、解約可能性を予測する機械学習モデルを組み込んだ顧客情報管理 App は、モデルの学習データとして使っていない新規顧客データに対して解約可能性を計算できるだけでなく、モデル作成に使った既存顧客データに対しても、そのデータの一部(特徴量)を変更して将来の解約可能性のシミュレーションをすることができるようになりました。
できました
今回は、Create ML を使って自分のカスタム App 用の Core ML モデルを作成し、実際にカスタム App に組み込んでみました。ちょっと長くなってしまいましたが、画像以外のデータを使った機械学習モデルの組み込み方法もおわかりいただけたのではないかと思います。
現時点では、FileMaker 単体で利用可能な Core ML モデルには制限がありますが、みなさんも簡単なモデルから始めて、機械学習機能がどのようなものか、ご自身のカスタム App で試してみてください。
なお、Core ML モデルを作成する方法にはもう一つ、Core ML コンバータを使って他ライブラリモデルを Core ML モデルに変換する方法があります。2021 年 3 月現在、以下の機械学習ライブラリを使って作成したモデルを Core ML モデルに変換することができます。
- 2021 年 3 月現在サポートされているライブラリ(バージョンはこちらを参照してください)
- TensorFlow 1
- TensorFlow 2
- PyTorch
- Keres
- ONNX
- Caffe
- XGboost
- scikit-learn
- LIBSVM
上記ライブラリを使ってモデルを作成したことのある方は、Core ML モデルへの変換とカスタム App への組み込みに挑戦してみてください。
なお、このブログ・シリーズでご紹介する機械学習機能は、FileMaker Pro 19 以降の macOS 版でご利用いただけます。19 よりも前のバージョンをお使いの方は、最新の無料評価版をダウンロードしてご利用ください。