
Claris FileMaker Pro 19 から Apple の Core ML による機械学習が利用できるようになりました。本ブログ・シリーズでは、FileMaker ビギナーズ & ジュニアズのみなさんに、FileMaker での機械学習がどういうものか、何ができるのか、どうやって使うのかなどについてざっくりご紹介します。
前回のブログでは、機械学習とは何か、FileMaker で機械学習を利用するということはどういうことかなどについて、これまでに公開されているセミナー動画とともにご紹介しました。
今回は、Apple から提供されている、Core ML に変換済みのモデルを使って、FileMaker で実際に機械学習機能を取り込む基本的な方法についてご説明します。
今回の旅路:
- Core ML に変換済みのモデルとは
- FileMaker で画像分類する
- ステップ 1:Core ML モデルをロードする
- ステップ 2:ロードしたモデルを使って分類する
- ステップ 3:Core ML モデルをアンロードする
- 分類を実行してみる
- エラーについて
- 次回は自分でモデルを作る!
なお、このブログ・シリーズでご紹介する機械学習機能は、FileMaker Pro 19 以降の macOS 版でご利用いただけます。19 よりも前のバージョンをお使いの方は、最新の無料評価版をダウンロードしてご利用ください。
Core ML に変換済みのモデルとは
Apple の Web ページには、様々な研究コミュニティによる学習済みのモデルが、Core ML モデルに変換されて提供されています。これらは既に学習済みなので、アプリに組み込んですぐに利用することができます。
Apple の Web ページで提供されているモデルは、次のものです(2021 年 3 月現在)。
- 画像
- 奥行き測定(FCRN-DepthPrediction)
- 手書き数字認識(MNIST)
- 線画識別(UpdatableDrawingClassifier)
- 画像識別(MobileNetV2)
- 画像識別(Resnet50)
- 画像識別(SqueezeNet)
- 画像セグメンテーション(DeeplabV3)
- オブジェクト検出(YOLOv3)
- (リアルタイム)オブジェクト検出(YOLOv3-Tiny)
- 姿勢推定(PoseNet)
- テキスト
- 質問応答(BERT-SQuAD)
ただし、残念ながらこれらすべてのモデルを FileMaker で利用できるわけではありません。前回のブログでもご説明したとおり、例えば、出力が画像であるものや、入力あるいは出力が多次元ベクトルのような複雑なタイプのものは、FileMaker 単体で利用することはできません。
上記のうち、FileMaker 単体ですぐに利用できるものは、MNIST、 MobileNetV2、Resnet50、 SqueezeNet です。下記の参考動画の 1、3、4 では、実際にこれらのいずれかを使って FileMaker での機械学習の利用方法が説明されています。
なお、PoseNet、YOLOv3、 BERT-SQuAD については、FileMaker 単体では利用できませんが、ブラグインを使って FileMaker で利用する方法が参考動画 1、2 で紹介されています。
参考動画:
- サンプルで学ぶ、Core ML による機械学習技術の実装
- Core ML による自然言語処理と物体検出
- FileMaker 19 Platform: Configure Machine Learning Model script step / CoreML support(英語)
- Train a CoreML Model and Put AI in Your Pocket(英語)
FileMaker で画像分類する
上記学習済み Core ML モデルのうち、MobileNetV2、Resnet50、 SqueezeNet はいずれもニューラルネットを使って画像分類をするモデルです。これらは ImageNet というカラー写真データベースのデータを使って学習しており、画像を 1,000 カテゴリに分類することができます。
まず今回は、FileMaker のカスタム App に SqueezeNet を組み込んで画像分類できるようにしてみます。他のモデル(MobileNetV2、 Resnet50)も使い方は同じなのですが、これらは前回のブログでご紹介した動画で取り上げられていますので、そちらもご参照ください。
カスタム App には、以下のような、ごく簡単なテーブルとレイアウトを用意しました。
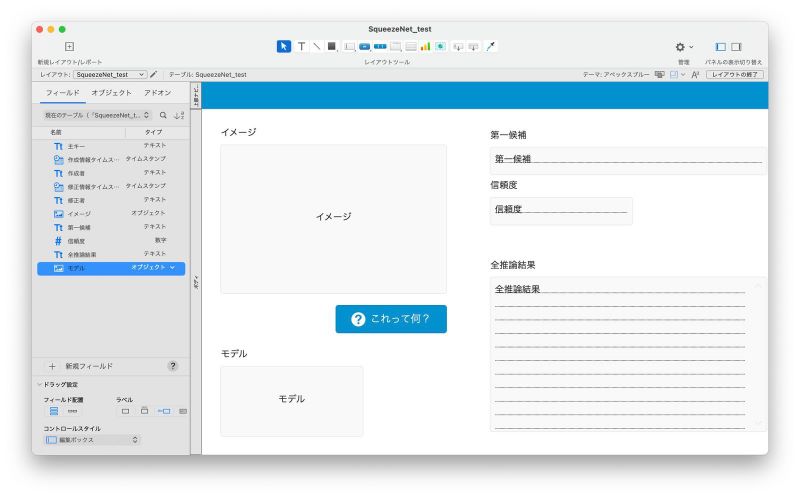
機械学習機能確認用のカスタム App
このレイアウトでは、「モデル」フィールドに格納した機械学習モデル SqueezeNet を使って、「イメージ」フィールドに登録された画像データに何が写っているかを判定します。
カスタム App の振る舞いとしては、ユーザが画像データを追加して、その下の「これって何?」ボタンをクリックすると、SqueezeNet で画像識別した結果を「第一候補」、「信頼度」、「全推論結果」の各フィールドに設定するようにします。「第一候補」、「信頼度」の各フィールドには最も信頼度が高い識別結果(分類名と信頼度の値)を、「全推論結果」フィールドには全識別結果を保存します。なお、「モデル」フィールドはグローバル格納フィールドとして定義しています。
それでは、「これって何?」ボタンに仕込む、実際に機械学習を実行するスクリプトを作っていきましょう。
ステップ 1:Core ML モデルをロードする
スクリプトではまず、FileMaker で機械学習するために使う Core ML モデルをロードします。
モデルをロードするには、[機械学習モデルを構成] スクリプトステップを使用します。例えば、今回のカスタム App では以下のように設定します。
上記スクリプトステップで指定している 3 つのオプションは、モデルをロードする場合の必須オプションです。
- [処理] は、画像を使った機械学習の場合は「視覚」、それ以外は「一般」を指定します(いずれも「」や””は不要)。
- [名前] は、使用するモデルに対して任意の名前を指定します。上の例では、”SqueezeNet” という名前を指定しました。名前を指定するために計算式を使用することもできます。このモデルの名前は、1 つのカスタム App ファイル内で一意である必要があります。例えば、2 つのカスタム App が同時に同じ名前を使ってモデルをロードしてもまったく問題ありませんが、1 つのカスタム App 内で複数のモデルを同じ名前でロードすると、先にロードされていたモデルがアンロードされてしまうので、カスタム App は想定外の振る舞いをするかもしれません。
- [次から] には、ロードする対象のモデルが保存されているフィールドを指定します。
この [機械学習モデルを構成] スクリプトステップの仕様については、FileMaker Pro ヘルプも参照してください。
ステップ 2:ロードしたモデルを使って分類する
次に、ロードした Core ML モデルを使って実際に画像を分類します。
モデルを使って分類、すなわち機械学習の結果を得るには、ComputeModel 関数を使います。今回のカスタム App のスクリプトでは、以下のように ComputeModel 関数の戻り値をローカル変数 $MLresult に設定して使用します。
変数を設定 [ $MLresult ; 値: ComputeModel ( “SqueezeNet” ; “image” ; SqueezeNet_test::イメージ ) ]
ComputeModel 関数の第 1 引数は、モデルの名前です。これは、ステップ 1 の [機械学習モデルを構成] スクリプトステップで指定した名前を使います。
第 2 引数以降は、モデルが必要とする引数を <名前> と <値> の対で指定します。指定する引数はモデルによって異なりますが、FileMaker で利用可能な「視覚」モデルの場合には次の 3 つの引数を指定できる仕様になっています。
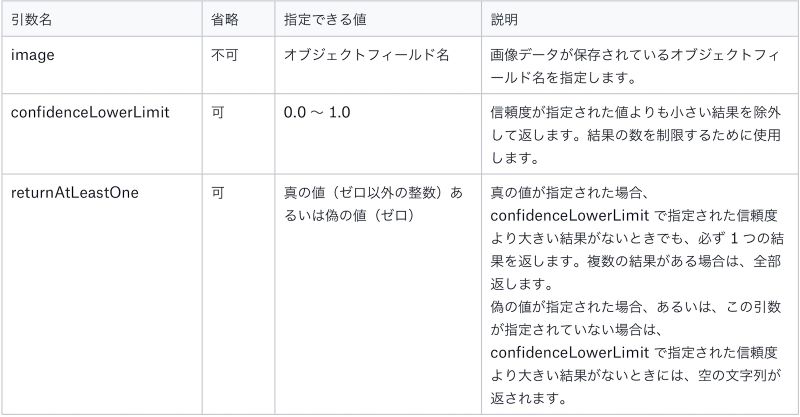
「視覚」モデルで指定できる引数
例えば、上記のスクリプトの中の ComputeModel 関数を次のように書き換えると、信頼度が 0.8 以上の結果が関数から返されます。信頼度 0.8 以上の結果が 1 つもない場合は、空の文字列が返され、変数 $MLresult に設定されます。
変数を設定 [ $MLresult ; 値: ComputeModel ( “SqueezeNet” ; “image” ; SqueezeNet_test::イメージ ; “confidenceLowerLimit” ; 0.8 ) ]
あるいは、次のように書き換えると、最も信頼度が高い結果 1 つだけが返され、変数 $MLresult に設定されます。
変数を設定 [ $MLresult ; 値: ComputeModel ( “SqueezeNet” ; “image” ; SqueezeNet_test::イメージ ; “confidenceLowerLimit” ; 1.0 ; “returnAtLeastOne” ; 1 ) ]
ComputeModel 関数の実行結果は、JSON 形式の文字列として返却されます。この内容も引数同様、モデルに依存しますが、「視覚」モデルの場合は次の 2 つのキーによるメンバーが 1 つ以上含まれる JSON 配列が返されます。このときの JSON 配列の要素の順序は、confidence(信頼度)の降順です。

「視覚」モデルで返されるJSON配列に含まれるキー
今回のカスタム App では、結果の JSON オブジェクトとその中の最初の、つまり、最も信頼度が高い JSON メンバーの値をフィールド値に設定して表示することにして、次のようなスクリプトを追加しました。
フィールド設定 [ SqueezeNet_test::第一候補 ; JSONGetElement ( $MLresult ; “[0].classification” ) ]
フィールド設定 [ SqueezeNet_test::信頼度 ; JSONGetElement ( $MLresult ; “[0].confidence” ) ]
フィールド設定 [ SqueezeNet_test::全推論結果 ; JSONFormatElements ( $MLresult ) ]
ComputeModel 関数の仕様については、FileMaker Pro ヘルプも参照してください。
なお、JSON 形式のデータをどうやって取り扱うか、ちょっと不安かも、という方は、FileMaker Pro ヘルプや Claris Web セミナーなどを参照してください。
ステップ 3:Core ML モデルをアンロードする
最後に、Core ML モデルをアンロードします。
モデルをアンロードする場合も、[機械学習モデルを構成] スクリプトステップを使用します。今回のカスタム App では以下のように記述します。
モデルをアンロードする場合のオプションは、[処理] と [名前] だけです。
- [処理] には「アンロード」を指定します。
- [名前] には、モデルをロードしたときに指定した名前を指定します。
このスクリプトステップを実行することによって、モデルがアンロードされ、モデルが使用していたリソース(メモリ空間など)を解放します。これは、iOS デバイスなど、リソースが限定されている環境で利用する場合には特に重要です。
開けたら閉める、出したら仕舞う、ロードしたらアンロードする。おうちでお母さんや奥さん(またはお父さんや旦那さん)にいつも言われている金言ですね。
分類を実行してみる
最終的に次のようなスクリプトを作成し、レイアウト上の「これって何?」ボタンがクリックされたら実行されるようにしました。モデルをロードして(1 行目)、モデルを使って推論して(3 行目)、推論結果をフィールドに設定して(5 〜 7 行)、モデルをアンロード(9 行目)するだけ。すごくシンプルですね!
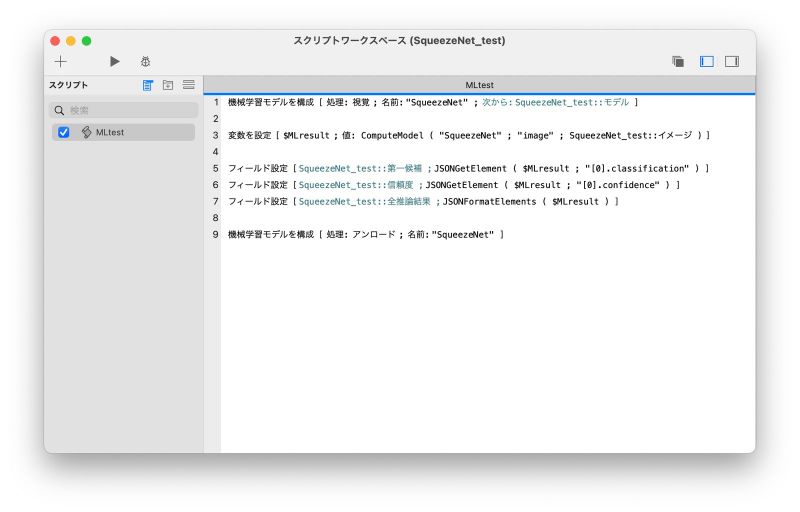
作成したスクリプト
出来上がったカスタム App は、以下のイメージです。
まず、グローバルフィールドとして定義している「モデル」フィールドに、Apple の Web サイトからダウンロードした SqueezeNet(SqueezeNet.mlmodel)のファイルを保存します。そして、「イメージ」フィールドに画像ファイルをドラッグ&ドロップしてみます。
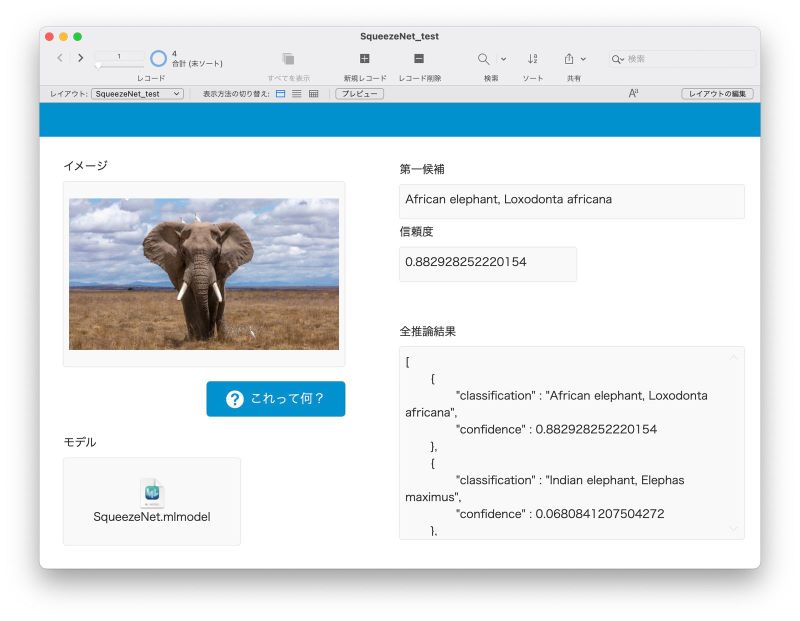
カスタム Appに「モデル」と「イメージ」を保存
そして「これって何?」ボタンをクリックしたら、「第一候補」フィールドに「African elephant, Loxodonta africana」、つまり「アフリカ象」とその学名が出てきました! 0 〜 1.0 の範囲の値をとる「信頼度」も 0.88 超と、なかなかの自信です。
「信頼度」の下の「全推論結果」には、ComputeModel 関数が返してきた JSON データをJSONFormatElements 関数で整形して表示しています。これをみると、このJSON データは JSON オブジェクトの配列になっていることがわかります。この配列の 1 番目の JSON オブジェクトは、上の「第一候補」および「信頼度」フィールドに設定していますが、続く配列の 2 番目の JSON オブジェクトを見てみると、分類(”classification”)が「Indian elephant」(インド象)、信頼度(”confidence”)は「0.068」と低い値になっています。つまり、SqueezeNet はこの画像を「アフリカ象」だとかなり確信している、ということですね。やるな!
別の画像も試してみましょう。
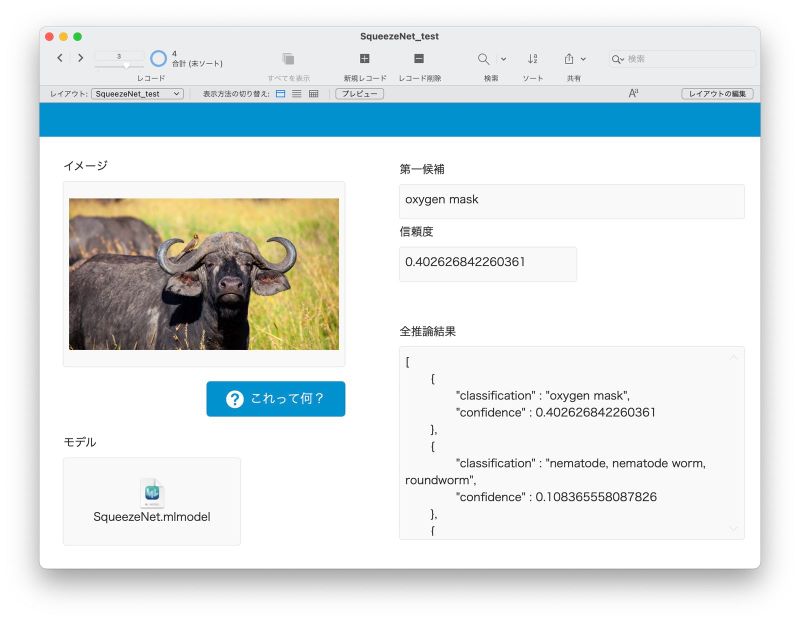
別の画像で試す
これは実は「アフリカ水牛」の写真なのですが、SqueezeNet による分類の「第一候補」は「oxygen mask」、酸素マスクだそうです…。「信頼度」は 0.4 なので、うん、やはり、あまり自信はないのでしょう。念のため「全推論結果」を見ると、2 番目の候補は「nematode」、線虫だそうで…(くるんとしたツノに惑わされていますね)。
ともあれ、以上で FileMaker で Core ML モデルを使った機械学習機能を利用するための方法を一通り確認することができました。
なお、上で説明した内容については、次の動画でも詳しく説明されていますので、ぜひ視聴してみてください。
- まだ間に合う!これから考える Claris FileMaker での機械学習活用(株式会社ジェネコム)
エラーについて
ここで、FileMaker Pro で機械学習を利用しようとした際によくあるエラーについてご紹介しておきます(既に試した方にはもうお馴染みかもしれませんが)。
Windows 版で実行した場合
FileMaker Pro 19 の機械学習機能は、macOS と iOS でのみ利用可能です。Windows 版で実行した場合、[機械学習モデルを構成] スクリプトステップでモデルをロードする際に、エラーになります(エラーコード [3])。
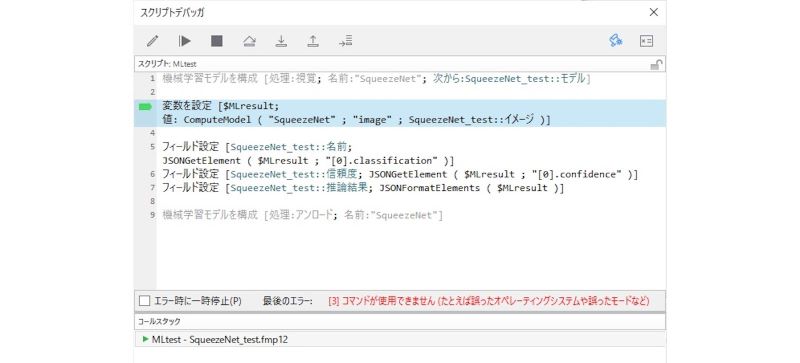
Windows 版ではモデルのロード時にエラー
FileMaker Pro 19 ではサポートしていないモデルを使った場合
本ブログの最初にご紹介したように、FileMaker Pro 19 では入出力データが複雑なモデルはサポートしていません。サポートしていないモデルをロードしようとすると、以下のようなエラーダイアログが表示されます。
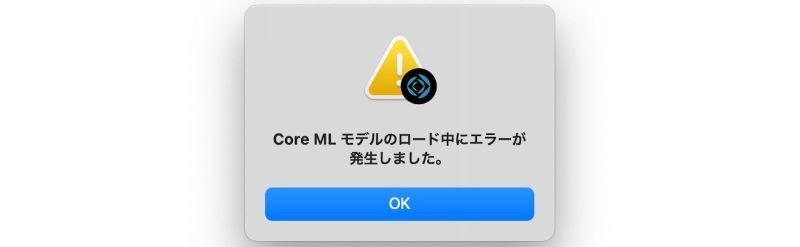
サポートされていないモデルをロードしようとした場合のエラーダイアログ
この場合は、エラーコード [871] のエラーが返されます。
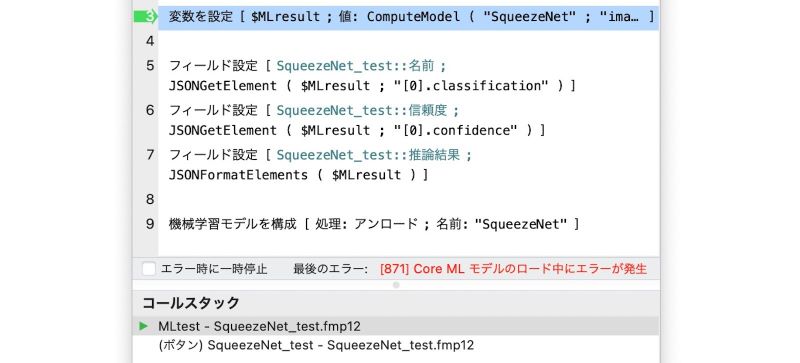
サポートされていないモデルをロードしようとした場合のエラー
モデル実行時に問題が起こった場合
モデルのロードでエラーにならない場合でも、入力データがそのモデルにそぐわないものであったり、モデルの出力データのタイプが複雑(多次元配列の場合など)だったりすると、CoputeModel 関数の戻り値として「? 」が返されます。この場合、エラーは返らないのでご注意ください。
次回は自分でモデルを作る!
今回見てきたように FileMaker で学習済み Core ML モデルを利用する方法はとても簡単です。しかし、自分が使いたい学習済みモデルが必ずしも提供されているわけではありません。というか、提供されているものをそのまま実際のカスタム App に使えるケースは、おそらくほとんどないでしょう。
そこで次回は、同じく Apple から提供されている Core ML モデル作成ツール Create ML を使って自分でモデルを作成してみます。Create ML は、ノーコードで Core ML モデルを作成できるスグレモノですので、乞うご期待!
なお、このブログ・シリーズでご紹介する機械学習機能は、FileMaker Pro 19 以降の macOS 版でご利用いただけます。19 よりも前のバージョンをお使いの方は、最新の無料評価版をダウンロードしてご利用ください。
次回、「FileMaker で機械学習やってみた (2)」はこちら!